Amazon EC2 Auto Scaling のライフサイクルフックを完了させる時の lifecycle-action-result とは
- この記事で書くこと / 書かないこと
- Amazon EC2 Auto Scaling のライフサイクルフック
- lifecycle-action-result について分からないこと
- 環境を用意
- インスタンスを Launchさせる時
- インスタンスを Terminate させる時
- まとめ
- 参考
この記事は DeNA 21新卒×22新卒内定者 Advent Calendar 2021 #DeNA21x22AdCal の23日目の記事です。
この記事で書くこと / 書かないこと
書くこと
- Amazon EC2 Auto Scaling のライフサイクルフックを完了させる AWS CLI コマンド
complete-lifecycle-actionのlifecycle-action-result引数(CONTINUE / ABANDON)について- どのような挙動をするのか
- Launch / Terminate 時
- ライフサイクルアクションが1つ / 複数ある時
- どのような場面で指定すべきか
- どのような挙動をするのか
書かないこと
- Amazon EC2 Auto Scaling の基本動作など
Amazon EC2 Auto Scaling のライフサイクルフック
Amazon EC2 Auto Scalingでは ライフサイクルフックという仕組みが使える。ドキュメントには以下のように紹介されている。
Amazon EC2 Auto Scaling は、Auto Scaling グループにライフサイクルフックを追加する機能を提供します。これらのフックにより、Auto Scaling グループは Auto Scaling インスタンスライフサイクルのイベントを認識し、対応するライフサイクルイベントが発生したときにカスタムアクションを実行することを有効にします。
ドキュメントにある図*1が分かりやすい。
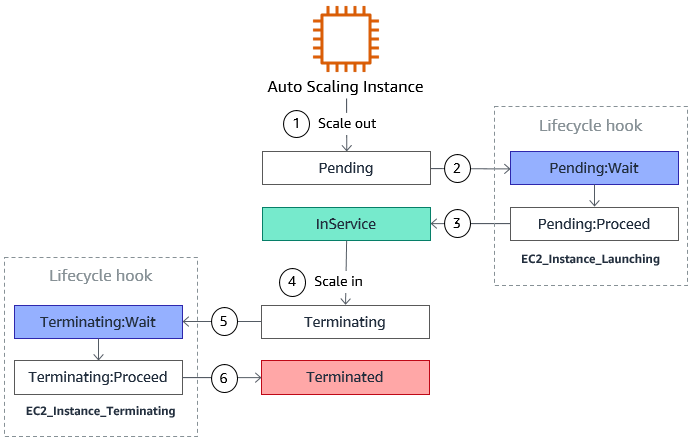
Pending:Wait/Terminating:Waitの間にやりたい処理を実行する- 処理が終わったら、ライフサイクルアクションを完了させる
Pending:Proceed/Terminating: Proceedに移行する- その後
InService/Terminatedとなる
というような流れである。Pending:Wait 時は プロビジョニングなどやるし、Terminating:Wait 時はログの収集などをやるだろうか。何かと便利。
lifecycle-action-result について分からないこと
先述した aws autoscaling complete-lifecycle-action のオプションに lifecycle-action-result というものがある。これに関してドキュメントにはこう書いてある。
lifecycle-action-result (string) The action for the group to take. This parameter can be either CONTINUE or ABANDON .
CONTINUE と ABANDON という値が取れることは分かった。しかし以下の 2点がよく分からない。
- どのような挙動をするのか?
- どのような場面で指定すべきか?
ドキュメントを漁ってみても、あまりめぼしい情報が出てこなかったので、手元のAmazon EC2 Auto Scaling 環境で実験してみることにした。
環境を用意
今回は以下の 4パターンにおける CONTINUE / ABANDON の挙動を確認する。
- EC2 インスタンスを Launch する時
- ライフサイクルフックが 1 つだけ作成されている時
- ライフサイクルフックが複数作成されている時
- EC2 インスタンスを Terminate する時
- ライフサイクルフックが 1 つだけ作成されている時
- ライフサイクルフックが複数作成されている時
上の挙動確認のために、 2つの AutoScalingGroupを用意した。
- ライフサイクルフックを Launch / Terminate 時のそれぞれ 1 つずつ作成した AutoScalingGroup
- ライフサイクルフックを Launch / Terminate 時のそれぞれ 2 つずつ作成した AutoScalingGroup
まず Auto Scaling の起動設定を作成。
❯ aws autoscaling create-launch-configuration \ --launch-configuration-name test-as-conf \ --image-id ami-xxxxx \ --security-groups sg-xxxxx \ --instance-type t2.micro
この起動設定からインスタンスを作成/削除する Auto Scaling グループを作成。上述した 2つの環境を設定にそれぞれ書いておく。
❯ vim test-asg.json
{
"AutoScalingGroupName": "test-asg",
"LaunchConfigurationName": "test-as-conf",
"LifecycleHookSpecificationList": [
{
"LifecycleHookName": "launch-hook",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_LAUNCHING"
},
{
"LifecycleHookName": "terminate-hook",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_TERMINATING"
}
],
"MinSize": 1,
"MaxSize": 1,
"DesiredCapacity": 1,
"VPCZoneIdentifier": "subnet-xxxxxx"
}
❯ vim test-asg-multiple-hooks.json
{
"AutoScalingGroupName": "test-asg-multiple-hooks",
"LaunchConfigurationName": "test-as-conf",
"LifecycleHookSpecificationList": [
{
"LifecycleHookName": "launch-hook-1",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_LAUNCHING"
},
{
"LifecycleHookName": "launch-hook-2",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_LAUNCHING"
},
{
"LifecycleHookName": "terminate-hook-1",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_TERMINATING"
},
{
"LifecycleHookName": "terminate-hook-2",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_TERMINATING"
}
],
"MinSize": 1,
"MaxSize": 1,
"DesiredCapacity": 1,
"VPCZoneIdentifier": "subnet-xxxxxx"
}
❯ aws autoscaling create-auto-scaling-group \
--cli-input-json file://./test-asg.json
❯ aws autoscaling create-auto-scaling-group \
--cli-input-json file://./test-asg-multiple-hooks.json
本来はこのライフサイクルフックに NotificationTargetARN を指定することで、SQS にジョブをキューしたり、Lambda を呼び出したりして、実行したい処理を呼び出す。今回はライフサイクルフック完了を CLI から直接行うだけなので、特に通知先は指定しない。
インスタンスを Launchさせる時
以上の設定で、ライフサイクルフックが 1つの環境も複数の環境も共に、既にインスタンスが 1台立ち上がり、ライフサイクルフックの完了を待っている(Pending:Wait) 状態になっている。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-01651d39583878c03",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Pending:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-06f48fba796571cbc",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Pending:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
CONTINUE
ライフサイクルフックが 1つの場合
lifecycle-action-result に CONTINUE を指定して、launch-hook という名前で作成したライフサイクルフックを完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "launch-hook" \
--auto-scaling-group-name test-asg \
--lifecycle-action-result CONTINUE \
--instance-id i-01651d39583878c03
インスタンスの状態を確認してみると LifecycleState が InService になっている。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-01651d39583878c03",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "InService",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
ライフサイクルフックが複数の場合
lifecycle-action-result に CONTINUE を指定して、2つのうちの 1つのライフサイクルフック(launch-hook-1) 完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "launch-hook-1" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result CONTINUE \
--instance-id i-06f48fba796571cbc
インスタンスの状態を確認してみると、ライフサイクルフックが 1つの場合は InService していたのに対して、まだ Pending:Wait のままである。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-06f48fba796571cbc",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Pending:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
では続いて、残りのもう 1つのライフサイクルフック(launch-hook-2) を、同じく lifecycle-action-result に CONTINUE を指定して完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "launch-hook-2" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result CONTINUE \
--instance-id i-06f48fba796571cbc
すると、全てのライフサイクルフックが完了したので、LifecycleState が InService となる。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-06f48fba796571cbc",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "InService",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
ABANDON
ライフサイクルフックが 1つの場合
今度は ABANDON を指定してみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "launch-hook" \
--auto-scaling-group-name test-asg \
--lifecycle-action-result ABANDON \
--instance-id i-06088732b011ec77c
インスタンスは Terminating:Wait となって、InService にはならない。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-06088732b011ec77c",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
ライフサイクルフックが複数の場合
lifecycle-action-result に ABANDON を指定して、2つのうちの 1つのライフサイクルフック(launch-hook-1) 完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "launch-hook-1" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result ABANDON \
--instance-id i-05f20b0925768e65a
ABANDON が指定されたため、1つ目を完了させた時点で2つ目のライフサイクルフックは無視され、Terminating:Wait となった。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-05f20b0925768e65a",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
インスタンスを Terminate させる時
勘の良い方はもう大体挙動が理解できたと思われるが、続いてインスタンスを Terminate させる時の挙動について確かめてみる。インスタンスは先ほどの実験の残りカスが Terminating:Wait のまま待機しているので、それを利用する。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-078955cc41ee3f010",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
CONTINUE
ライフサイクルフックが 1つの場合
lifecycle-action-result に CONTINUE を指定して、terminate-hook という名前で作成したライフサイクルフックを完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "terminate-hook" \
--auto-scaling-group-name test-asg \
--lifecycle-action-result CONTINUE \
--instance-id i-06088732b011ec77c
その後インスタンスを確認してみると、LifecycleState が Terminateing:Proceed となる。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-06088732b011ec77c",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Proceed",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
少し待てば完全に Terminate され、AutoScalingGroup からいなくなる。
ライフサイクルフックが複数の場合
lifecycle-action-result に CONTINUE を指定して、2つのうちの 1つのライフサイクルフック(terminate-hook-1) 完了させてみる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "terminate-hook-1" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result CONTINUE \
--instance-id i-05f20b0925768e65a
CONTINUE したので、Terminate 時でも、もう1つのライフサイクルフックが完了するまで Terminating:Wait のままである。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-05f20b0925768e65a",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Wait",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
続いて2つ目(terminate-hook-2)を完了させる。
aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "terminate-hook-2" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result CONTINUE \
--instance-id i-05f20b0925768e65a
全てのライフサイクルフックが完了したので、Terminating:Proceed となり、しばらくしたら LifecycleState が Terminatedとなる。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-05f20b0925768e65a",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Proceed",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
ABANDON
ライフサイクルフックが 1つの場合
ABANDON を指定して terminate-hook を完了させる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "terminate-hook" \
--auto-scaling-group-name test-asg \
--lifecycle-action-result ABANDON \
--instance-id i-078955cc41ee3f010
Terminate させる時は、CONTINUE と同じく、Terminating:Proceed となる。 ABANDON は 「中断」という意味だが、インスタンスを減らすことを中断するわけではない。
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-078955cc41ee3f010",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Proceed",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
ライフサイクルフックが 複数の場合
ABANDON を指定して 2つのうちの 1つのライフサイクルフック(terminate-hook-1) を完了させる。
❯ aws autoscaling complete-lifecycle-action \
--lifecycle-hook-name "terminate-hook-1" \
--auto-scaling-group-name test-asg-multiple-hooks \
--lifecycle-action-result ABANDON \
--instance-id i-0aa497f0729a2a0bf
❯ aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-name test-asg-multiple-hooks \
| jq ".AutoScalingGroups[].Instances[]"
{
"InstanceId": "i-0aa497f0729a2a0bf",
"InstanceType": "t2.micro",
"AvailabilityZone": "us-east-2a",
"LifecycleState": "Terminating:Proceed",
"HealthStatus": "Healthy",
"LaunchConfigurationName": "test-autoscale",
"ProtectedFromScaleIn": false
}
こちらも Launch 時と同じく、複数のライフサイクルフックがあったとしても、ABANDON を指定した場合はその他のライフサイクルフックは無視される。問答無用でインスタンスは Terminating:Proceed へと移行し、やがて Terminated となる。
まとめ
Amazon EC2 Auto Scaling のライフサイクルフックを完了させる時の lifecycle-action-result の挙動について、実際にコマンドを打ちながら確認した。まとめると以下のような感じ。
| CONTINUE | ABANDON | |
|---|---|---|
| Launch × 1つのライフサイクルフック | InService |
Terminated |
| Launch × 複数のライフサイクルフック | インスタンスは他のライフサイクルフックが完了されるのを待つ → 全てのライフサイクルフックが完了すると InService |
Terminated |
| Terminate × 1つのライフサイクルフック | Terminated |
Terminated |
| Terminate × 複数のライフサイクルフック | インスタンスは他のライフサイクルフックが完了されるのを待つ → 全てのライフサイクルフックが完了すると Terminated |
Terminated |
CONTINUE- ライフサイクルフックを次のステップに進める
- ライフサイクルフックが複数あるなら、残りのライフサイクルフックの結果を待つ
- 完了していないライフサイクルフックが無くなったら、
InService/Terminatedになる
- フックした処理が成功した場合に指定することが多い
- ライフサイクルフックを次のステップに進める
ABANDON
それでは皆様もよい AutoScaling ライフを!
参考
{kind=link}
リモートワークを気付いたら1年もやっている
去年の4月くらいからアルバイト先でリモートワークをしていた。つまりリモートワークを始めて、かれこれ1年が経った。今現在は新卒で入社した会社でこれまたリモートで研修を受けている。この1年で特に困ったことはなく、自分はリモートワーク適性があるのかもしれない。
リモートワーク、めちゃくちゃ得意かもしれない、悩みが0
— みしま a.k.a. オーディン (@odmishien) 2021年4月8日
リモートワークについて何をしたか、どう思っているかを雑にまとめてみた。
設備
- 1K10畳に住んでいる
- 無印の机を買った(120×70×72)
- 机が広くないと生産性が上がらない
- 多少散らかってもストレスがたまらない程度には大きい机が良い
- PCはクラムシェルモード で LGの34インチのウルトラワイドモニター に繋いでいる
- クラムシェルなのでカメラは外付けになるが、とりあえず 適当なもの を買った
- 画質良くはないが、別に困ってもいない
- キーボードはHHKB Pro2、マウスはApple純正のMagic TrackPad2
- 椅子はありものを使っているが、そろそろ社のオフィスチェアが譲渡される
- ヘッドセットは AfterShokz OPENCOMM
- 骨伝導じゃないと耳垂れがすごいことになっておしまいになる
- 個人差ありそう、私はAirPodsProくらいしか試してないので他にもいいモノがあるかもしれない
- コーヒーとお菓子は切らさないようにする
- 余裕があればハンドドリップ、余裕がなければマシンで入れている
- マシンは友人から譲ってもらったのをそのまま使っているのでいつかもっといいモノにしたい
優れている点
- 当たり前だが、通勤しない分の時間を手に入れることができる
- ドア to ドアで往復1hしかかからないと仮定しても1週間で5h, 1ヶ月で20hくらい手に入れられる
通勤時しかできないことってそこまでない気がしている- 歩きたい → 散歩に行けばいい
- 本が読みたい → 読めばいい
- やっぱり電車に乗りたい → 何駅か隣の街に出かければいい
- 出勤/退勤/休憩開始/休憩終了 がシームレス
- 昼休みに寝慣れたベッドにダイブできること
- 退勤直後に寝慣れたベッドにダイブできること
- 近所のお気に入りの店にランチに行けること
- これは居住エリアとオフィスのあるエリアの比較になりそう
- 気軽に気を抜ける
- マイクをミュートして、カメラをオフにしてしまえば、いくらでもリラックスできる
- 本当に疲れた時に一旦リラックスできるという手段を持っているいうことにより、心理的ゆとりが生まれる
困っている点
- 雑談が減る
- 減る
- これはDiscordやGatherみたいなアプリで解決できそう
- Discord気に入ってきた - hitode909の日記
失われていたオフィスでの立ち話したり、隣の人のメンバーと漠然と話したり、がようやく手に入った
- Discord気に入ってきた - hitode909の日記
- しかし社によってはセキュリティポリシー的な話もあって導入が難しいケースもあるのかもしれない
- ミーティングのやりやすさがミーティング相手のマイクの質に左右される
- 音質がざらざらしている人と話をするのは耳が疲れるし、聞こえづらいものを聞こうとするので対面よりも疲れる
- いいマイクを買ってほしいけど、会社の福利厚生でリモートワーク補助されてない場合はどうしようもない
- 一度も会ったことがない人と関係を築いていくことが難しい
- これが1番大変かもしれない
- とはいえ対話するしかない
- 対面よりも丁寧に1on1や進捗確認的なものをやる
- 対面よりも自己開示する部分を増やしたり、オーバーにリアクションをしたりする
- なんとかして雑談を増やす
こうやって書き上げてみると、多少困っているようだった。困りは今後解消したい。
もちろんリモートワーク最高という話も聞くが、反対にリモートワークのせいで鬱になるみたいな話も聞いた。このへんはチームや企業の状態にもよるし、個人の適性にもよりそう。色々織り交ぜた働き方もあると思うので、二元論として対立させるのではなく、いい感じに知見が集まればいいなと思う。
Twitterの人たちは「何になった僕」を見てほしいのか調べてみた
この記事と同じようなことでもう1つ気になったことがあるので、調べてみました。
香水/瑛人 は去年とても流行りましたね。その中で私が好きな一節がこちらです。
でも見てよ今の僕をクズになった僕を
唐突な告白に聞いている人は皆何があったのか気になったと思います。ドルチェ&ガッバーナがどうとかは良いんですが、この部分が気になりすぎて過去を詮索したくなります。
さて、Twitterでは早速この一節を替え歌にして楽しんでいる方々が散見されました。私も例に漏れず、やっております。
フグになった僕を♪
— みしま a.k.a. オーディン (@odmishien) 2021年1月12日
これ、Twitterの人たちは「何になった僕」を見てほしいんだろう....という疑問が湧きました。早速調べてみます。
TweetをAPI経由で取得する
サクッとPythonで実装してみます。TwitterAPIのwrapperは色々ありますが、使ったことのなかったsearchtweetsを使用してみました。
実際のコードは以下のような感じです。
from searchtweets import load_credentials, collect_results, gen_request_parameters import csv import datetime search_args = load_credentials("./creds.yaml", yaml_key="search_tweets", env_overwrite=False) rule = gen_request_parameters( "になった僕を -is:retweet", since_id=${SINCE_ID}) tweets = collect_results(rule, max_tweets=1000, result_stream_args=search_args) rows = [] for tweet in tweets: try: rows.append([tweet['id'], tweet['text'].replace( '\n', '').strip()]) except: pass with open(f'results/result_{datetime.datetime.today().strftime("%Y_%m%d")}.csv', 'w') as f: writer = csv.writer(f) writer.writerows(rows)
かなりシンプルでリツイートではない「になった僕を」という文字列を含むtweetを直近7日間から取得してCSVファイルにします。 since_id を指定するとそのIDのツイート以降のツイートだけを集めることができるので、これを定期的に実行する際に指定しておきます。
load_credentials の部分は以下のようなyamlファイルを渡しています。
search_tweets: endpoint: https://api.twitter.com/2/tweets/search/recent bearer_token: ${YOUR_TOKEN} consumer_key: ${YOUR_CONSUMER_KEY} consumer_secret: ${YOUR_CONSUMER_SECRET}
「でも見てよ今の僕を◯◯になった僕を」の部分を抽出してカウントする
これは先述のQiitaの方のコードをほとんど使わせていただきましたので割愛します。
re.compile('でも見てよ今の僕を.+になった僕を')
こんな感じの正規表現を使います。ここで抽出された単語の数は229種類となりました。後はPythonの collections.Counter でカウントします。
結果
気になる結果です。
1位: クズ(154tweets)
やはり本家の言い回しが1番しっくりくるのか、2位に大差を付けて堂々の1位。
2位: デブ(13tweets)
食べ過ぎた時に言い訳に使えそうです。
2位: 鬱(13tweets)
見てもらわなくていいので、然るべき医療機関に診てもらいましょう。
4位: 猫(8tweets)
🐈🐈🐈🐈🐈🐈🐈🐈🐈
5位: 神(5tweets)
夜神月か?
個人的に好きだったもの
- でも見てよ今の僕をちんこになった僕を
- シンプルイズベスト!
- でも見てよ今の僕をアチいドロドロに溶けたアチい鉄になった僕を
- 何があった
- でも見てよ今の僕をおちんちん丸出しになった僕を
- しまって
- でも見てよ今の僕を朝寒くて服を脱ぎたくなかったからスウェットの上から作業着着てドムみたいになった僕を
- 想像すると面白い
- でも見てよ今の僕を投稿頻度オリンピックくらいになった僕を
- 4年に1回
- でも見てよ今の僕を”完全”になった僕を
- "最終回" だ
- でも見てよ今の僕を爆乳大陸パンゲアになった僕を
- どこ?
皆さんも良い香水ライフを!
はてなのエンジニアアルバイトを退職しました
表題の通りです。いわゆる退職エントリ~アルバイト版~ です。1月25日が最終出社日でした(しかし物理出社はご時世なのでしていない...)。辞める理由は全くネガティブなものでなく、単に大学院卒業が近付いてきて、内定先でインターンすることなどが決まって稼働時間が確保できなくなりそうなので早めの退職、という感じです。
きっかけ
2019年の夏、大学の友人から「はてなはイイぞ」と言われ、「ヘ〜そうなのか」と思ってなんとなく応募したのがきっかけでした。元々はてなブログやブックマークなどのメジャーどころは触っていたのですが、正直なところ、根っからのはてなー!という感じではなかったです。当時の私はプログラミングをかじり始めてまだ1年ほどだったので、かなりダメ元で応募したのですが、トントン拍子で話が進んで働くことになりました。 面接ではこれまで作ってきたもの(ほぼ実績などなかったが)の話や京都が好きだという話をしたことをぼんやり覚えています。今思い返すとたまたま枠が空いていたのかなという気がするくらい、周りのエンジニアアルバイトの方のレベルが高くて驚いたのですが、それと同時にとても刺激的な環境でした。

入社当時はロクなはてなidを持っていなかったのですが、人事の方に「idどうしますか?」と聞かれ咄嗟にその時使っていたTwitterのID(![]() id:odmishien)を使うことになりました。結構難読idなので少し後悔しましたが、「おでんくん」「オーディン」などとフレンドリーに呼んでくださる方もいて、なんだかんだ良かったのかなと思っています。これからもこの業界ではodmishienとしてやっていきます。
id:odmishien)を使うことになりました。結構難読idなので少し後悔しましたが、「おでんくん」「オーディン」などとフレンドリーに呼んでくださる方もいて、なんだかんだ良かったのかなと思っています。これからもこの業界ではodmishienとしてやっていきます。
働き方
私は神戸在住なのですが、はてなのオフィスは烏丸御池にあるのでJRと地下鉄を乗り継いで通勤することになりました。学部4回生〜M1くらいまでは週3回ほど通勤していましたが、不思議と苦ではなくて、電車の中で寝たり本を読んだりSwitchをしたりとなかなか充実した通勤生活でした。 何よりも最高だったのがオフィスまかないでした。残念ながら昨年の春くらいから現在まではコロナの影響で食べていませんが....*1。週に一度カレーの日というのがあって、サイコーでした。ドリンクもスナックもフリーなので苦学生には助かりっぱなしの福利厚生でした。
コロナで世の中がアレになってからはリモートワークが推奨されるようになり、例に漏れず私も在宅勤務に切り替わりました。リモートワークになっても元々テキストコミュニケーション文化が強く根付いている環境だったので、業務に支障をきたすなあと思ったことは1度もありませんでした。
何をしたのか
SPF時代
入社してすぐはサービスプラットフォーム部(通称SPF)に配属されることになりました。採用サイトによると
はてなのサービスおよび事業を支える基盤を開発・運用するチーム。はてなのコンテンツプラットフォームのよりよい体験を長く支えていくための、多くのサービスやソフトウェアを担当しています。
みたいなチームです。当時ははてなダイアリーが終了してはてなブログへと統合されるというタスクの真っ只中という感じで、ブログ系のお仕事をやっていました。他にもはてなフォトライフ や人力検索はてななどの古くからあるプロジェクトの保守運用やユーザーサポートのスタッフの方が利用する管理画面などの整備も担当していました。他にも古くなった開発環境をDocker化するなど、エンジニアの業務がスムーズになるような仕事も担当させていただいていました。 言語としてもかなり色々触らせていただいて、PerlはもちろんGo, TypeScript, React などなど。 仕事に慣れてくるとクラウド基盤プロジェクトというものに片足を突っ込ませていただき、AWSのCDKを触ってみたり、k8sを触ってみたりとちょっと今っぽいことを体験させていただきました。
SPF部では10年前のコードを触ることもあれば自分が1から書くコードもあったりして、とても刺激的で得るものの多い環境だったなと今になって感じています。また、エンジニアとしての立ち回りというか、振る舞いみたいなものもここで多くを教わったなと思っています。
- 作業ログを冗長めに残すこと
- 要件から必要なものを少し先読みして動くようにすること
特にこの2つはいただいたフィードバックから色々と自分なりに実践をしてみて、退職直前になってやっと板についてきたかな...という感じです。絶対にこれからのエンジニア人生で役に立つ心構えだと思うので、これからも精進しよう...。


ブログチーム時代
コロナで世の中が大変になってからはリモートワークが中心になってしまった&研究と就活でまとまった稼働時間が取れなくなってきた、ということでより適性のありそうなブログチームに異動となりました。 とは言ってもSPFに所属している頃からブログ関連のタスクはいくつか担当していたので、ヌルッと業務に参画することができて良かったです。基本的にははてなブログのバックエンドのバグ修正や改修、新機能の追加などをやっていました。
ここでもリモートワークの勘所みたいなものを多く学ばせていただきました。テキストベースのコミュニケーションはもちろん、必要な時に素早くGoogleMeetなどでペアオペに付き合ってくださった社員のみなさまのおかげで、スムーズにお仕事を進めることができました。
まとめ
はてなで働いた約2年半は間違いなく私のエンジニア人生を大きく変えました。はてなには(エンジニアかそうでないかに関わらず)呼吸をするようにインターネットを良くしよう、インターネットで得たことをインターネットに還元しよう、ということを体現してらっしゃる方が多くて、これは本当に稀有な環境だったなと思います。インターネットはどこまでも続いているので、私も呼吸をするようにインターネットを少しでも良くしていけるような人間になりたいと心に決めたのでした。
最後に、はてなで関わってくださった全ての方に感謝したいと思います。ありがとうございました&お世話になりました!!!! またどこかでお会いしましょう!!!
*1:現在は全社的にオフィスランチは実施されていません
Webフロントエンド何も分からんがGatsbyを使ってポートフォリオを作り直してみる
はじめに
こんにちは。 odmishienです。この記事はDeNA 21 新卒 Advent Calendar 2020の12日目の記事です。実は4日目も担当していました。
4日目に書いた記事はどちらかというと技術的な話というより勉強法や精神論的なポエムだったので、今回は技術ネタを持ってきました。
私はアルバイトの業務では主にバックエンドを担当していて、特にPerl, Python, Go などを書くことが多いです。Webフロントエンド何それ美味しいのという感じで、Vue.jsを趣味のプロダクトで使ってみたことがあり、かろうじてコンポーネントを理解している…というようなレベルです。
でも....カッコよくて便利なポートフォリオが欲しい.....!!!!
そんな気持ちが、ポートフォリオになりました❤︎
今回はWebフロントエンドをバリバリに書いたことのない私がGatsby.jsを使ってポートフォリオサイトを作るにあたってやってみたことをまとめてみようかと思います。
これまでのポートフォリオの問題点
なんとも言えないパフォーマンス
以前作っていたポートフォリオはVue.jsで作成してGitHubPagesでホストしていました。Lighthouse Report Viewerのスコアがこんな感じ。

そこまで重たいコンテンツを置いているわけではないのですが、スコアが微妙。
コンテンツをHTMLにベタ書きして更新しなければならない
ポートフォリオなので作ったものを掲載したりしていたのですが、これを手動でやっていました。具体的には以下のようなコンポーネントを作成してそこに props を渡したものを毎回書いていました。
<template>
<div class="card">
<img class="card-img-top" width="100%" height="50%":src="src" />
<div class="card-body">
<h4 class="card-title">{{ title }}</h4>
<p class="card-text">{{ text }}</p>
<div class="row my-2">
<a
v-if="appLink"
class="btn btn-primary col-4 offset-2"
target="_blank"
:href="appLink"
>Check App</a>
<a v-if="githubLink" class="col-4" target="_blank" :href="githubLink">
<LogoGithubIcon w="40px" h="40px"></LogoGithubIcon>
</a>
</div>
<div class="tags">
<p v-for="tag in tags" class="card-text text-muted">#{{ tag }}</p>
</div>
</div>
</div>
</template>
<script>
import LogoGithubIcon from "vue-ionicons/dist/logo-github.vue";
export default {
name: "card",
components: {
LogoGithubIcon
},
props: {
imgPath: {
type: String,
required: true
},
title: {
type: String,
required: true
},
text: {
type: String,
required: true
},
appLink: {
type: String,
default: null
},
githubLink: {
type: String,
default: null
},
tags: {
type: Array,
required: true
}
},
data() {
return {
src: require(`../assets/${this.imgPath}`)
};
}
};
</script>
新しいものを作成するたびにポートフォリオの方も修正して、buildして、pushして....みたいなことをしていて、結構面倒でした。
手動でビルドしないといけない
GitHubPagesを使っていたので、決まったブランチの決まったディレクトリにpushさえすればデプロイはできたのですが、手元でwebpackを使ってbuildしてあげる必要がありました。よくコマンドを忘れてhistoryから探したり、「あれ?ビルドしたっけ?」となることがあったりして、少し不便でした。
そもそもGatsby.jsとは何か
Gatsby is a React-based open source framework for creating websites and apps. Build anything you can imagine with over 2000 plugins and performance, scalability, and security built-in by default.
- なんか早い
- なんかプラグインで色々簡単に拡張できる
- なんかコマンドポチポチしたらサイトができてる
とにかく導入が簡単!コマンドを打つだけで複雑な設定は隠蔽してくれます!!というインターネットの声をよく目にしました。こういうなんでもやってくれる系のフレームワークはお節介が過ぎると敬遠してしまう場面もありますが、Webフロントエンドに精通していない私にとっては手取り足取りして欲しい!ということでGatsbyを導入してみることにしました。
プロジェクトの作成方法など、Gatsbyのコマンドに関する話はここでは割愛させていただきます。(インターネットにたくさん良記事が転がっていた記憶があります)
構成
ある程度長くメンテナンスするだろうなということとお勉強のためにTypeScriptを選びました。Reactを使うのはGatsby.jsの場合避けられません。
ホスティングはこれまでも使っていて使い慣れているGitHub Pagesを採用しました。また、デプロイも親和性の高いGitHub Actionsで行うことにしました。
GitHubのリポジトリ情報にGraphQL経由でアクセスする
ldd/gatsby-source-github-api を使います。
READMEの通りに設定していきます。まずは gatsby-config.js にプラグインを追加します。
{ resolve: "gatsby-source-github-api", options: { token: process.env.GITHUB_API_TOKEN, graphQLQuery: ` query ($nFirst: Int, $q: String!) { search(query: $q, type: REPOSITORY, first: $nFirst) { edges { node { ... on Repository { id name description url } } } } }`, variables: { q: "topic:portfolio user:odmishien", nFirst: 10, }, }, }
今回は portfolio というtopicが指定された 私のリポジトリを10件取ってくる設定になっています。これで人様に見せてもいいと思うリポジトリには portfolio というtopicを付けておくだけでOKです。
そしてindexページのtsxファイルの中でGraphQLでデータにアクセスします。
import { IndexQuery } from "../../types/graphql-types" interface IndexProps { data: IndexQuery } const IndexPage: React.FC<IndexProps> = ({ data }) => { const repos = data.githubData?.data?.search?.edges ... // 省略 } export const query = graphql` query Index { githubData { data { search { edges { node { id name description url } } } } } } `
ひとまずこんな感じでリポジトリとそのdescriptionを表示させることに成功。

GraphQLのクエリの構築に結構苦戦しましたが、GitHub GraphQL API Explorer で型の補完を効かせながら試行錯誤しました。
また同じようなことを自分の技術ブログ(はてなブログ)のRSSフィードから生成するみたいなことをmottox2/gatsby-source-rss-feedを使って実現しています。
GraphQLのスキーマをTypeScriptの型に落とし込む
GraphQLを使ってAPIなどのレスポンスを使えるのは便利なのですが、その構造を型に落とし込むのを手動でやっていくのはちょっと骨が折れます。先ほど触れなかったのですが
import { IndexQuery } from "../../types/graphql-types"`
としている部分があったことにお気付きでしょうか。これは私が定義したのではなく、 gatsby-plugin-graphql-codegen を使って、型定義ファイルを自動で生成しています。
またも、gatsby-config.jsの中にプラグインを書いていきます。
{ resolve: "gatsby-plugin-graphql-codegen", options: { fileName: `types/graphql-types.d.ts`, }, }
これで types/graphql-types.d.ts というファイルに gatsby build されるたびに発行しているqueryに応じて、型定義が追加されていきます。
例えば私のポートフォリオの場合、index.tsの末尾に以下のようなIndexという名前のクエリを発行しています。
export const query = graphql` query Index { ...省略 } `
ビルドしてみると、この名前に Query というsuffixが付いた IndexQuery という型が定義されているのが確認できます。便利!
GitHub Actionsを使って決まった時間に自動デプロイ
GitHubやRSSから欲しい情報を取ってくることはできますが、コンテンツの更新はビルドし直さないとできません。そこでmasterにpushがあった時と毎日夜0:00にビルドしてGitHub PagesにデプロイするというActionを仕込みます。これはkentaromさんの記事がとても参考になりました。
name: Deploy on: push: branches: - master schedule: - cron: "0 0 * * *" jobs: build-and-deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: setup node 14.x uses: actions/setup-node@v1 with: node-version: "14.x" - name: install run: npm install - name: build run: npm run build env: GITHUB_API_TOKEN: ${{ secrets.GITHUB_TOKEN }} - name: deploy uses: peaceiris/actions-gh-pages@v3 with: github_token: ${{ secrets.GITHUB_TOKEN }} cname: your.domain.com # 独自ドメインを利用したい場合
secrets.GITHUB_TOKEN の方はActionsのworkflow内で使える自動で生成されたトークンなのでsecretsに登録する必要がありません1。便利!
peaceiris/actions-gh-pages は github_tokenを指定しておくだけで、デフォルトで gh-pagesブランチにpublicディレクトリの内容をデプロイしてくれます。カスタマイズしたかったらこれらの値をyamlに書いてあげてください。
また、独自ドメインを利用したい場合は cname フィールドに利用したいドメインを指定しておきます。これをしないとデプロイの度にCNAMEファイルが作られないので、毎回デフォルトのURL(https://username.github.io)が指定されてしまいます。
まとめ

無事読み込みも速くなって、オールグリーン!ビルドやデプロイのことはGitHub Actionsが全て担ってくれるので、私がやることはなくなりました。サイコー!Webフロントエンドのことをあまりよく分かっていない私でもある程度のセッティングができたので便利ですね、Gatsby!!
改善点としては
npm installを毎回やってしまっているので、キャッシュする- GraphQLについてかなりフィーリングで触っているので勉強して無駄のないクエリを書く
- 掲載するコンテンツを増やす
などでしょうか。随時手を入れていこうと思います。
最後までお読みいただきありがとうございました。
参考になった記事
文系でもソフトウェアエンジニアになれますか?
はじめに
こんにちは ![]() id:odmishienです。この記事はDeNA 21 新卒 Advent Calendar 2020の4日目の記事です。ひょんなことから内定をいただき、4月からソフトウェアエンジニアとしてDeNAで働くことになりました。
id:odmishienです。この記事はDeNA 21 新卒 Advent Calendar 2020の4日目の記事です。ひょんなことから内定をいただき、4月からソフトウェアエンジニアとしてDeNAで働くことになりました。
さて。修論執筆でパンク寸前の中、何を書こうとウンウン唸っていました。技術的な話を書きたい気持ちもあったのですが、他の同期がとても優秀な記事を書いてくださるだろうという甘えと、もしかして大学も大学院も文系である私がDeNAでソフトウェアエンジニアになることは少し珍しいのでは?と思い、結果としてこんなタイトルになりました。かなりポエミーというか、技術的な話はほとんど出てこないのですが、よろしければお付き合いください。
想定読者
- 文系だけどソフトウェア開発に興味がある方
- (理系ではあるが)非情報系だけどソフトウェア開発に興味がある方
- お暇な方
WHO AM I
まずは簡単に私の経歴をお話しします。(割とどうでもいいので飛ばし読みしてもらって構いません)
中学・高校時代からPCを触ったりゲームをしたりするのは好きでしたが、自分がそれを作ってみよう!などとはつゆも思わず。数学がありえないほど苦手だったのもあり、大学入試は小論文と英語だけで乗り切りました。特に興味のある学問もなかったので、特定の分野(法学/経済学など)はやめて、ぼんやりと広く学べそうな教養系っぽい学部を選んだのを覚えています。大学に入学してからも3年生になるまではヨーロッパの政治だったり、ジェンダー問題についての講義を受けたりしていました。アルバイトもフレンチ料理屋さん、コンビニ、スイーツ工場など、プログラミングのプの字も出てこないようなものを転々としていました。
プログラミングに初めて触れたのは学部の3年生の時のとある講義だったと記憶しています。現在修士の2年生なので、一応プログラミング歴は3年と少しということになります。教養系なので「情報コミュニケーション」というコースが存在していて、そこの単位がチョロいらしいという不純な動機で履修した講義でした。Pythonの文法を一通りやってから、簡単なWebアプリを作ってみようというような内容だったと思うのですが、なんだかとてもワクワクしました。気付いたらかなりのめり込んでしまって、講義以外でもプログラミング学習サイトでPythonを読み書きしていました。
それからは自分の生活を豊かにするためのコーディングをよくやっていました。簡単なリマインダーをしてくれるLINEBotを作ったり、クレジットカードの引き落としを通知してくれるスクリプトを書いたり。本来なら学部の3年生なので就活をするものなのですが、合同説明会やサマーインターンなどもあまり気乗りせず、休みの日にするコーディングの方が私の心をワクワクさせてくれました。4年生になって配属されるゼミでは社会システム科学というものを扱うところに配属されました。情報技術を使って、社会学/統計学/心理学などをやりましょう!という文理学際的なゼミです。とはいえ情報科学や計算機科学にはほとんど触れません。ITパスポートを取るとえらい!基本情報技術者を取るとすごい!みたいな世界線をイメージしてくださるといいかと思います。
ある日、ゼミの教授と飲んでいて、「大学院おいでよ〜」と軽いノリで言われました。(おそらく教授は酔っていてほとんど覚えていないと思われる。) それは文系の私にとってはかなり盲点でした。「大学院に行けばもっとコードを書けるのでは!?」とはしゃいで帰ったのを覚えています。早速就活を中断し、願書を用意することにしました。この頃には開発のバイトも始めたりしていたと思います。
大学院に無事合格し、入学までの間にも大きな転機がありました。割と有名なWeb系の会社のアルバイトの面接に合格し、アプリケーションエンジニアとして働くことになったのです。著名なOSSのコミッターやあのツールを作った方なんですか!?みたいな方と一緒にお仕事をできるということでワクワク半分、恐ろしさ半分で初出社したのを覚えています。
そこでの経験も積んで、修士の1年生の夏にエンジニア向けのサマーインターンに初めて参加しました。それに関しては色々書いた記事が別にあるので、もし興味があればどうぞ。弊社もサマーインターンに参加したことをきっかけに採用面接も受けたという流れです。とても刺激的な夏でした。
文系でもソフトウェアエンジニアになれるのか
結論から言うと、文系でもソフトウェアエンジニアにはなれます。結局文系/理系なんぞ、日本の教育システムが生み出した構造にすぎないし、アルバイト先にも「本当に文系出身か?」というようなツヨツヨな方もいます。ただ、これは生存者バイアスとも言い切れません。実際私の場合も、開発のアルバイト先での環境がとても良かったり、ある程度自律的に学習を継続することができたというのが大きく寄与しているとは思います。
とは言うものの、私の持論として「何かを知りたいならとにかくサンプル数(N)を増やせ」というものがあります。数多の「こういうことが役に立ちました」「こういう意識を持つとよいのかもしれません」というものの中に意外と自分にしっくりくるtipsが転がっているかもしれないからです。そんなNのうちの1つになれば幸いです。
まず何をするべきか
よく聞かれるのが「まず何から始めたらいいですか?」という問いです。この問いには様々な考え方や答えがあると思います。私がプログラミングを学び始めて1年の間にやったことを振り返ってみると、大きく分けて3つのことをやったと記憶しています。
1. とにかく1つ言語を選んで学習教材を一周する
ここで自分のプログラミング学習への適性(?)のようなものが分かる気もしています。純粋に黒い画面に何やら意味の分からないコードを打つのが楽しい、よく分からないけどハッカーのような気分になれて嬉しい、などと思える方は適性ありです。私の場合は言語はPython、学習教材にはpaizaラーニングを使いました。
ここで注意すべきなのは以下の点です。
- 言語は1つに絞ること
様々なプログラミング言語がありますが、学習を始めたての頃にいくつも学ぶ必要は全くありません。1つの言語をある程度書けるようになれば、第2・第3の言語を習得するのはさほど時間がかからないので、まずは1つの言語の文法や仕様を理解することに注力しましょう*1。
- 教材を1つに絞ること
私の場合は無料のオンライン講座を教材に選びました。これが良かったのか悪かったのかは分かりませんが、動画でかわいい声優さんが教えてくれる点やインタラクティブに教材が進んでいく点は、個人的に合っていたと思います。教材は書籍でもオンライン講座でも構いませんし、課金することが苦にならないならプログラミングの教室に行っても構いません。とにかく1つの教材を完全に終わらせることを目標にして、あれこれと手を出さないようにしておきましょう。
2. 作りたいモノを作る
なんだか突然話が進んだような気もしますが、1つ言語をマスターすれば次は作りたいモノを作りましょう。あくまでもプログラミング言語はソフトウェアを開発するツールであり、それを駆使してモノを動かしてみないことにはあまり意味がありません。サンプルプログラムやインターネットに落ちているプログラムをとにかくいじり倒してみましょう。決して綺麗なコードである必要はありません。まずは動けばいいの精神で臨みましょう。また、いくつかモノを作っていると様々な問題に直面します。こうした問題を自分で調べて解決する力*2は実際にソフトウェアエンジニアとして働くようになってからも、とても重要なスキルの1つだと思うので、とにかく手を動かしましょう。
という話をすると「特に作りたいモノがないです....」と言われたことがあります。そういう場合は 他人の欲しいモノを作るのがオススメです。
「他人の欲しいモノを作る」というのは別に全世界に最高のアプリを公開しましょう、という話ではなく、家族や友人との生活のなかで「こういうのあったら便利だよな〜」という声を聞き逃さないようにしましょうという意味です。例えば私の場合は「飲み会の日程調整するのが面倒!」と言っている友人のために「ランダムな日付で起動して"飲み会しよや!"と発言してくれるLINE bot」を作ったり、「サークル活動で班分けをいちいち考えるのが面倒!」と言っている友人のために「人の名前のリストを指定した人数のグループに分けてくれるスクリプト」を作ったりしました。
決して完璧なソフトウェアを作る必要はありませんし、万バズするようなソフトウェアである必要もありません。自分やその身の回りにいる人が少し助かるようなモノで構いません。この時期に作ったモノが、今でも私のソフトウェア開発の原動力でもあり、ソフトウェアエンジニアを志すきっかけとなりました。
3.作ったモノをエンジニアに見てもらう
ここまでくれば、「ソフトウェアエンジニアです!」と名乗ってもよさそうなくらいです。しかし、個人で作ったプロダクトと世の中で動いている大規模なプロダクトとの間にはいくつもの差があります。リッチなフロントエンド、大量のデータを格納しても問題の発生しないDB設計、大量のトラフィックに耐え得るサーバー構成...。挙げるとキリがないですが、やはりプロが作るようなモノを一朝一夕で作れるようにはなりません。
プロになるには実際にプロに教えを乞うのが1番です(もちろんプロでなくても自分より詳しい先輩でも構いません)。ただ、彼らも0から手取り足取り教えてくれる訳ではありません。そこで役立つのが「作ったモノ」なのです。ソフトウェアエンジニアは基本的に「モノづくり」が大好きで、動いているモノがどう設計されたのか/どう実装されているのかという話をするのが好きで好きでたまりません。誰でも初めはビギナーなので、恥ずかしがらずに汚いソースコードを見てもらいましょう。きっと、「こう設計した方が綺麗だ!」とか「こう実装した方が美しい!」とか「俺だったらこうする!」とか色々と耳寄り情報を与えてくれるでしょう。
という話をすると、「周りにコンタクトを取れるエンジニアがいないです....」 と言われたことがあります。この辺りで私は運が良く、自分よりもソフトウェア開発に関して詳しい方と話す場が多かったと思います。 あなたが学生であれば、どの大学にもプログラミングサークル的な団体が存在すると思うので、勇気を出してそのドアを叩きましょう。また自分の大学の情報系学科の教授にコンタクトを取ってみるのも良い手かもしれません。心優しい教授であれば、きっと快くお話ししてくれると思います。
学生じゃないので無理だ....という方も諦めないでください。エンジニアが集まる場所は他にもいくつかあります。その中でもおすすめなのがconnpassなどで開催されている勉強会です。
こんな感じで「初心者・学生に優しい」というカテゴリが用意されていて、一緒に切磋琢磨できる仲間や色々と教えてくれる先輩エンジニアを見つけることができるかもしれません。
この辺りはコミュ力というか、フットワークというか、そういう力が求められるのでちょっとツラいですが、ソフトウェアエンジニアは様々な人とコミュニケーションを取る必要のある職業だと思うので、訓練だと思って頑張りましょう。ご時世的にオンラインでのイベントも増えているので参加しやすいとも思います。
どういう学習をするべきか
次によく聞かれるのが「独学でどういう学習をしたんですか?」という問いです。これも個人差があると思いますし、まだまだ私も日々勉強中の身です。そんな中でボンヤリと思っていることを書いてみます。
付け焼き刃をどんどん大きくして使える刀にしていく
「付け焼き刃」という言葉はあまりいい意味で使われる言葉ではありません。しかし(賛否両論/適性などあると思いますが)個人的には初期のプログラミング学習において、この「付け焼き刃」のような勉強に良い点があると考えています。あなたが情報系学徒のように体系的に学ぶ場の用意されていない非情報系であるなら、尚更です。
プログラミング学習で最も大きな壁になるのはモチベーションの低下だと思っています。これを維持することができず、頓挫しました....というのも珍しくないと思います。やはり人間なのでゴールの見えない道のりに立たされるとゲンナリしてしまうものです。そこで、とにかくゴールを小さく設定しましょう。
例えば初めから体系的に「Webとは何か」を理解する必要はないと思います。「そういうものがあるんだな」「よく分からないけどこうしたら動くんだな」というような付け焼き刃をどんどんやっていきましょう。まずは動かす。動かすためにググる。よく分からないけどコードを貼り付けたら動いた。それでいいのです。
こうやって勉強を進めると、コードが実際に動く喜びをこまめに感じることができます。
ある程度刀が大きくなるとどこかで刀が折れてしまうので今度はきちんと鋳型に入れてみる
とはいえプロになっていったソフトウェアエンジニアが「よく分からないけど動いている」状態のままボーッとしているかというと、もちろん違います。体系的な学習や理解を疎かにしてはいけないが、後回しにはしていいというのがこの例えの趣旨です。大きくなった付け焼き刃はいつかどこかで折れてしまいます。でもその頃にはきっと折れた刀を溶かして鋳型に入れれば、きちんとした刀が作れるはずです。どこまで体系的にやれるか、というのは非情報系学生の永遠の課題ですが、網羅的な書籍や公式ドキュメントなどを読む癖を徐々につけていきましょう。徐々に、で構わないと思います。インプットばかりでツラくなったら、また作りたいモノを作って発散しましょう。
どういう立ち回りをするべきか
最後に立ち回りという言葉が正しいかどうか分かりませんが、こういうことをやっていたのは良かったなというものを紹介します。
自分が「ソフトウェアについて1番知らない環境」と「ソフトウェアについて1番詳しい環境」のどちらにも身を置いてみる
これは本当にオススメで、可能ならぜひこれからも続けたいなと思っていることの1つです。私にとって「自分がソフトウェアについて1番知らない環境」が今のアルバイト先で、「自分がソフトウェアについて1番詳しい環境」が在籍している研究室やもう1つの学生主体で運営しているアルバイト先かなと思っています。
学習していくにあたって、インプットとアウトプットのバランスというのは重要だと思います。しかし、1つの場所でその両方の質を確保するのは難しいでしょう(初学者であれば尚更)。ならば、インプットする場所とアウトプットする場所を分けてみればよいのです。
アルバイト先では基本的に社員さんの多いチームで働いていて、周りにあまり学生がいませんでした。隣のチームにいる学生のアルバイトの方も相当優秀で、日々圧倒されています。そうした場所でもらうコードレビューやソフトウェア開発に臨む姿勢みたいなものはとても質が高く、得るものも多いです。とはいえこうした場所でアウトプットまでやろうとするには、そこまで手が回らなかったり、釈迦に説法だな...などと思ってしまって遠慮がちになってしまったりしがちでした。
反対に研究室や学生主体のアルバイト先では、後輩がたくさんいて、色々と分からないことや困っていることを聞いてくれる機会が多いです。もちろん知っていることを答えるというのは、自分の中での理解を進めることがあったり言語化する力が付いたりと良いことづくしです。また知っていると思っていたことを、いざ他人に説明するとなると「あれ、これってどうなっているんだっけ?」と再確認するきっかけにもなります*3。
とにかくメモを残しておく
人間とは愚かなもので、たくさんのことを忘却していく生き物です。プログラムを書いていても「なんかこのエラー前も見たな...なんだっけ...」とGoogle検索を叩くということを何度もやっています。そこで役に立つのがメモです。個人的なおすすめはScrapBoxですが、後から検索する術があるものであればなんでも(OS標準のメモ帳でも)構いません。
網羅的で先進的な技術ブログみたいに書く必要はなく、あくまでも自分用のメモだと思って書くと、些細なことでも残す癖がつきます。これは実際にアルバイト先でも役に立っている習慣の1つで、
- 同じミスや問題をすぐに解決することができる
- どうしても分からないことがあればメモを元にして識者と会話ができる
- (もしそのメモが社内でアクセスできるものであれば)同じ問題で躓いている人の助けになるかもしれない
など、良いことづくしです。
原点を忘れないでおく
最後に突然の精神論ですが、個人的に大切なことは自分がソフトウェアエンジニアになろうと思った原点だと思います。私自身何度も「コーディングをやりたくない」「自分よりも優秀な人はごまんといるのだから私がやる必要がない」などと悩んだことがあります。その度に思い出すのが、初めて自分が作ったソフトウェアが動いた日の感動であり、初めて自分が作ったソフトウェアを人に褒められた時の喜びです。
- なぜ自分がコードを書く必要があるのか
- 何がソフトウェア開発の喜びなのか
- ソフトウェア開発のどこが好きなのか
こうしたことを自分の中で言語化するのは、明確な動機にも繋がると思います。
もちろん言語化していく中で「やはり私はエンジニアにならなくてもいいのでは」「ソフトウェア開発は好きだけど別に”コーディング”は好きではないな」など様々な気付きもあると思います。そういう時はエイッとプログラミングから距離を置いてみるのも手です。道は決して1つではないし、コードを書かずともソフトウェア開発に関われる仕事はたくさんあります。自分を大切にしましょう。
おわりに
気付いたらちょっとしたレポートくらいの長さになってしまいました。この筆の勢いのまま修論を提出して、無事に4月から社会人になりたいと思います。最後までお付き合いいただきありがとうございました。もし何か聞きたいことや物申したいことがあれば、 Twitter などでご連絡ください。またどこかでお会いしましょう!!
宣伝
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter や facebook、はてなブックマークにてコメントをお願いします。 また DeNA 公式 Twitter アカウント @DeNAxTech では、 Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローしてみて下さい。チョー有益です。
OpenWeatherMapのWeatherAPIでFreeプランだけど明日の天気を取得したい
Freeプランでは明日の天気をDaily Forecastから取得できない
ちょっとハマったので記録を残しておく。 卒論生の作っているアプリでOpenWeatherMapのWeatherAPIを使っている。
今日の天気を取るのは簡単で、Current weather data - OpenWeatherMap を使えば良さそう。
問題は明日の天気の取り方で、Daily Forecast 16days を使えば簡単に取れるだろ〜とか思っていたら、Freeプランでは使えないAPIだった…。
>> curl http://api.openweathermap.org/data/2.5/forecast/daily?units=metric&q=Kobe&appid={YOUR_API_KEY}&cnt=1
{"cod":401, "message": "Invalid API key. Please see http://openweathermap.org/faq#error401 for more info."}
ちゃんとドキュメントに書いてあったので、ちゃんとドキュメント読もうねという気持ちになった。
解決方法その1: One Call APIを使う
大体必要そうな気象情報を返してくれる便利なエンドポイントで、無料アカウントでも利用することができる。ちなみに取得できる情報は
- 現在の天気
- 直近1時間分の分ごとの天気予報
- 直近48時間分の時間ごとの天気予報
- 直近7日分の日ごとの天気予報
- 政府の出している気象警報
- 5日前までの気象データ
である。この中の直近7日分の日ごとの天気予報を取ってくれば良さそう。
curl http://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&exclude=current,minutely,hourly,alerts&appid={YOUR_API_KEY}
exclude というパラメータに不要な項目を渡すことができる。あとはレスポンスからよしなに明日の天気を取り出すだけである。
注意すべきなのは 緯度軽度でしか検索ができない点である。都市の名前やZIPコードで検索したい場合は緯度経度への変換が必要になってしまうので、一手間かかる。
解決方法その2: 5 day weather forecast APIを使う
こちらも無料アカウントで利用できる。直近5日間の天気予報を返してくれるエンドポイントなのだが、注意すべきなのは3時間ごとにデータが区切られている点である。
今日のAM6:00をスタートとして、5日分の天気予報を3時間ごとに渡してくれる。cnt というパラメータを用いて、何個分のデータを取得するかを決められるようになっているので、明日の必要な時間までのデータを受け取るように cnt を指定する。例えば明日のAM9:00の天気は、今日のAM6時から27時間後のデータなので、 27 / 3 = 9 を cnt に指定する、といった具合である。(多分デフォルトで cnt は最大に設定されていそうなので、cnt を設定しなくても大丈夫そうではある。)
curl http://api.openweathermap.org/data/2.5/forecast?q={city name}&cnt=9&appid={YOUR_API_KEY}
{
"cod": "200",
"message": 0,
"cnt": 40,
"list": [
{
"dt": 1596564000,
"main": {
"temp": 293.55,
"feels_like": 293.13,
"temp_min": 293.55,
"temp_max": 294.05,
"pressure": 1013,
"sea_level": 1013,
"grnd_level": 976,
"humidity": 84,
"temp_kf": -0.5
},
"weather": [
{
"id": 500,
"main": "Rain",
"description": "light rain",
"icon": "10d"
}
],
"clouds": {
"all": 38
},
"wind": {
"speed": 4.35,
"deg": 309
},
"visibility": 10000,
"pop": 0.49,
"rain": {
"3h": 0.53
},
"sys": {
"pod": "d"
},
"dt_txt": "2020-08-04 18:00:00"
},
...
"city": {
"id": 2643743,
"name": "London",
"coord": {
"lat": 51.5073,
"lon": -0.1277
},
"country": "GB",
"timezone": 0,
"sunrise": 1578384285,
"sunset": 1578413272
}
}
data['list'] の中に3時間ごとのデータが入っているので、お目当ての 明日のAM9:00のデータは data['list'][10] に入っている。
エンドポイント多すぎて混乱するので、何か間違っているかもしれません.....。ご指摘お待ちしてます!!